21.2 Example
Per program which you want to manage, you must create an entry under 'Administrate jobs'. We would like to present the most important values using an example:
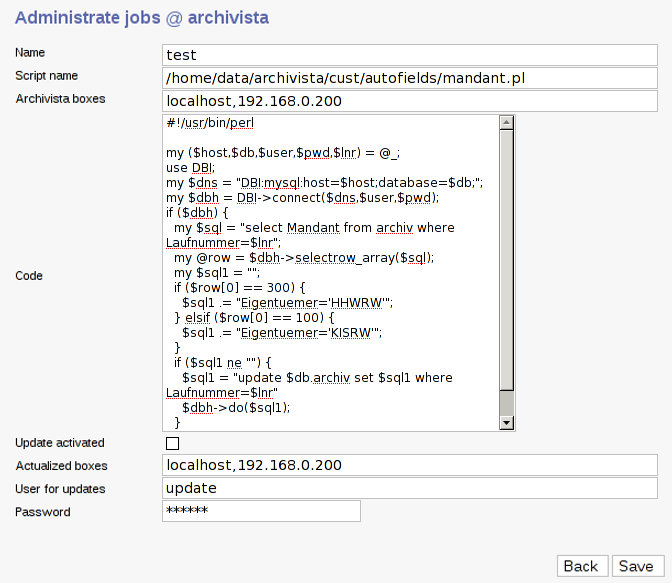
For clear identification use 'Name'. For 'Script Name', use the entire path including the program. For 'ArchivistaBoxes', enter the IP addresses of the monitored Archivista Boxes. For 'Code', we find the program code. If 'Update is activated', then the corresponding programs are also monitored in the local directories of each ArchivistaBox. Under 'Updated ArchivistaBoxes', you will find the IP addresses of the ArchivistaBoxes which already possess the current version of the program.
In 'User for updates' and 'Password', you must specify the user which you previously set for the same ArchivistaBox (Master). The last two entries are necessary in order for the monitored ArchivistaBoxes to be able to inform the Master Instance whether or not the current version is available on the peripheral station. This requires more rights than a normal user would normally receive; therefore an appropriate user must be created.
 When a document is saved, there is always a check if there is a script with the same name as the database with which the user is working. This script must be manually transferred to ArchivistaBox. For the database 'archivista' it would have to be copied to the following location:
When a document is saved, there is always a check if there is a script with the same name as the database with which the user is working. This script must be manually transferred to ArchivistaBox. For the database 'archivista' it would have to be copied to the following location:
/home/data/archivista/cust/autofields/archivista.pl
Please note that the script needs rights for execution (e.g. for the example above chmod a+x archivista.pl).