22. Archive erstellen
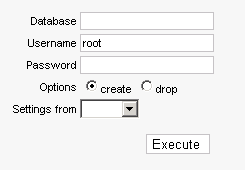
Das Formular, um Archive zu erstellen oder zu löschen, sieht dem Login-Formular sehr ähnlich.
Subsections
Das Formular, um Archive zu erstellen oder zu löschen, sieht dem Login-Formular sehr ähnlich.